

Tech Blog
見せてもらおうか、OKIの「PCAS」の性能とやらを…!

よろしくお願いします!!
こんにちは、小野あらため、オノ・アズナブルです。
今回は、PCAS(Pruning Channels with Attention Status)ツールを実際に使って、AIモデルを軽量化、その性能、実力を徹底的に暴いてやります!乞うご期待!!
前回からの続編になりますので、まだ前回をご覧になっていない方は、こちらも是非ご覧ください。
PCASの仕組み

今回はいよいよPCASツールでAIモデルを軽量化していくぞ!

その前に質問です。PCASは枝切りによって、AIモデルの中の不要なニューロンや接続を取り除く技術というのは理解しました。
その枝切りのステップをもう少し詳しく教えてもらおうか…。
まあ、気にしないでください。

ふむ、そこの解説はしていなかったか。
PCASはattention、prune、trainという3つのモードを
順番にループさせて軽量化するという仕組みなんだ。
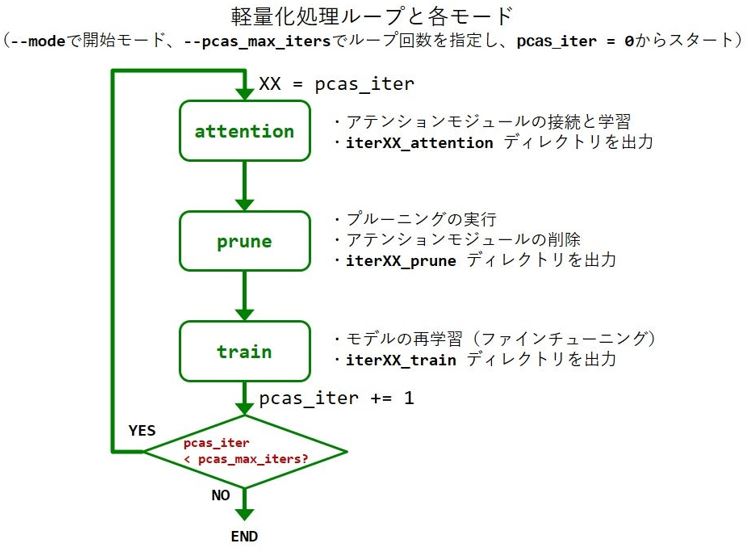

アテンションモジュールの接続と学習を行うんだ。
アテンションモジュールは、ニューラルネットワークの
畳み込み層の出力に挿入する小型モデルのこと。
全ての層に対してこれを実施して、アテンション統計量を取る。推論結果に大きく寄与していればしているほど、高い値を出力するんだ。

しかし、枝切りを行っただけでは、モデルの精度の
劣化が起きてしまう。
一度落ちた精度を回復させるんだ。この3つをループ制御し、少しずつAIモデルを軽量化していくんだ。
生成される。これは学習モデルの計算やパラメータの数、更新された重みなどが含まれていて、いわば軽量化の進捗をまとめたファイルなんだ。
楽ちんだと思うんですけど…。
1ループで一気に軽量化する設定にしてしまうと、必要なニューロンもまとめて削除されてしまって精度がガクンと落ちてしまう可能性が高いんだ。
でも少しずつ軽量化することで精度の劣化を抑えられるから、後でやってみたときの結果を楽しみにしてくれ。
実際にその傾向が見られるのか気になります。
PCASを利用して結果を見てみたくなってきました!
PCASの実行
データセットを活用して軽量化しようか。
モデルはVGG11を使用します。

ちなみにCIFAR 10は10クラス分類の画像データセットです。VGG11は8層の畳み込み層と3層の全結合層、
合計11層からなる畳み込みニューラルネットワークです。
ターミナルからPCASループを含む“train_plain.py”というファイルを実行するんだ。学習と軽量化を分けて行うこともできるけど、今回は学習と軽量化を連続実行してみよう。
python examples/classification/train_plain.py \
--outdir /path/to/output \
--data_dir /path/to/cifar10 \
--dataset cifar10 \
--model vgg11_cifar \
--pl_module classifier_plain \
--mode train \
--pcas_max_iters 6 \
--max_epochs 200 \
--learning_rate 0.1 \
--finetune_lr_ratio 0.5 \
--batch_size 128 \
--devices 1
--outdir /path/to/output \ 出力データの生成ディレクトリの指定(指定がなければ自動で生成)
--data_dir /path/to/cifar10 \ 使用データセットのディレクトリの指定
--dataset cifar10 \ 使用するデータセットの指定
--model vgg11_cifar \ 使用するAIモデルの指定
--pl_module classifier_plain \ 登録した関数の呼び出し
--mode train \ 開始時のモード指定(通常はtrainを指定)
--pcas_max_iters 6 \ イテレーション(重みの更新)回数の指定(軽量化実施前の学習を含む)
--max_epochs 200 \ 最大のエポック数(計算回数)の指定
--learning_rate 0.1 \ 学習率の指定
--finetune_lr_ratio 0.5 \ ファインチューニングの学習率の指定
--batch_size 128 \ バッチサイズの指定
--devices 1 \ 使用するGPU数の指定
PCの環境
CPU: Xeon2123 3.60GHz コア数:8
GPU: GeForce RTX 2070 SUPER
OS: Ubuntu20.04.6
Nvidia ドライバー:476.256.02
CUDA:11.3
初めてのAIモデル軽量化ですけど、まずは半分くらいのサイズに削減してみたいです。
イテレーション“pcas_max_iters”だよ。
各イテレーションにおけるモデルの圧縮率を追加で指定できたりするんだ。
とくに指定がなければ、デフォルトで15%だ。
少し時間がかかるんですね。この感じだと数時間程度かな。

お楽しみに!!
数時間後…
ドキドキです…!
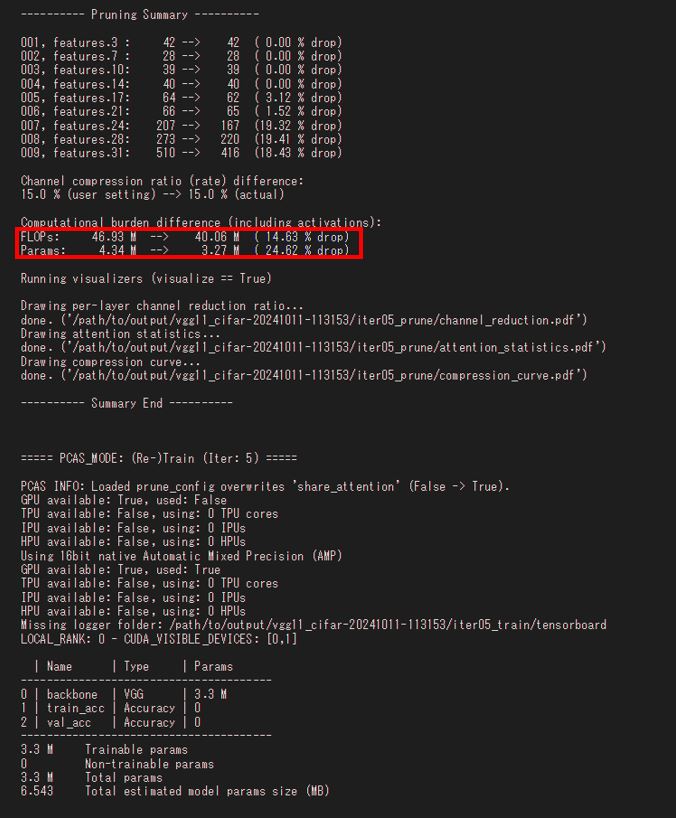
どこを見ればわかるのかな。
- 軽量化1回目
- 軽量化5回目
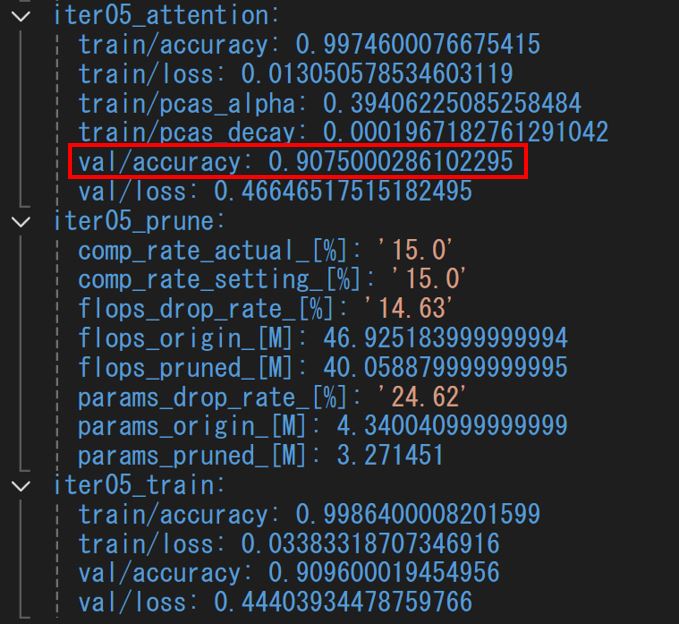
モデルサイズはどのように確認するのでしょうか?
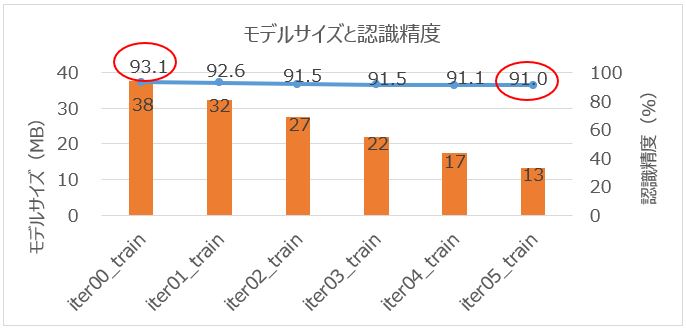
認識精度は93.1%から91.0%に変化して、2%程度落ちていますが、モデルサイズは38MBから13MBまで削減することができています。
おおぉぉぉ!認識精度をほぼ維持しつつ約65%モデルサイズを削減できているではないかぁ!!
計10回軽量化してみる
どこまでモデルサイズを削減できるか試してみましょうよ!
見せてもらおうか、その実力を!!
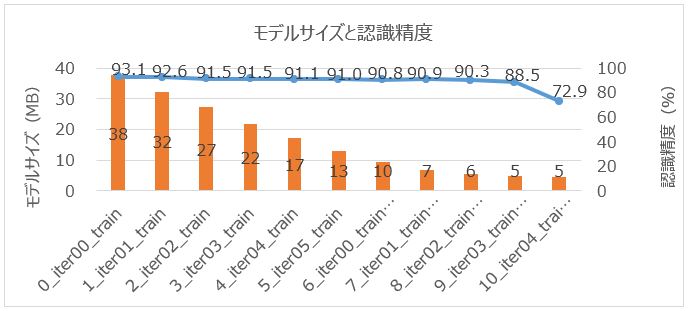
9回目のプルーニング後に認識精度が少し落ち始めていて、プルーニング10回目で大きく落ち始めているね。
一方、モデルサイズは8回目、9回目のプルーニングあたりからあまり変化が見られなくなりました。
ということは9回目がAIモデル軽量化の限界のようですね!!
圧縮率を変えてみる
モデルサイズをどの程度小さくするかに大きく関わるのが、圧縮率というパラメータなんだ。これを変えるとどのような結果になるのか…?
今までの軽量化では圧縮率はデフォルトの15%です。
今度は圧縮率10%と30%それぞれで試してみます。PCASループを実行するときに圧縮率を指定できるんですよね。
python examples/classification/train_plain.py \
--outdir /path/to/output \
--data_dir /path/to/cifar10 \
--dataset cifar10 \
--model vgg11_cifar \
--pl_module classifier_plain \
--mode train \
--pcas_max_iters 10 \
--max_epochs 200 \
--learning_rate 0.1 \
--finetune_lr_ratio 0.5 \
--batch_size 128 \
--comp_rate 0.10 \ 圧縮率30%のときは0.3に設定
--devices 1
ふむふむ、さっきと同じようにグラフにまとめます。
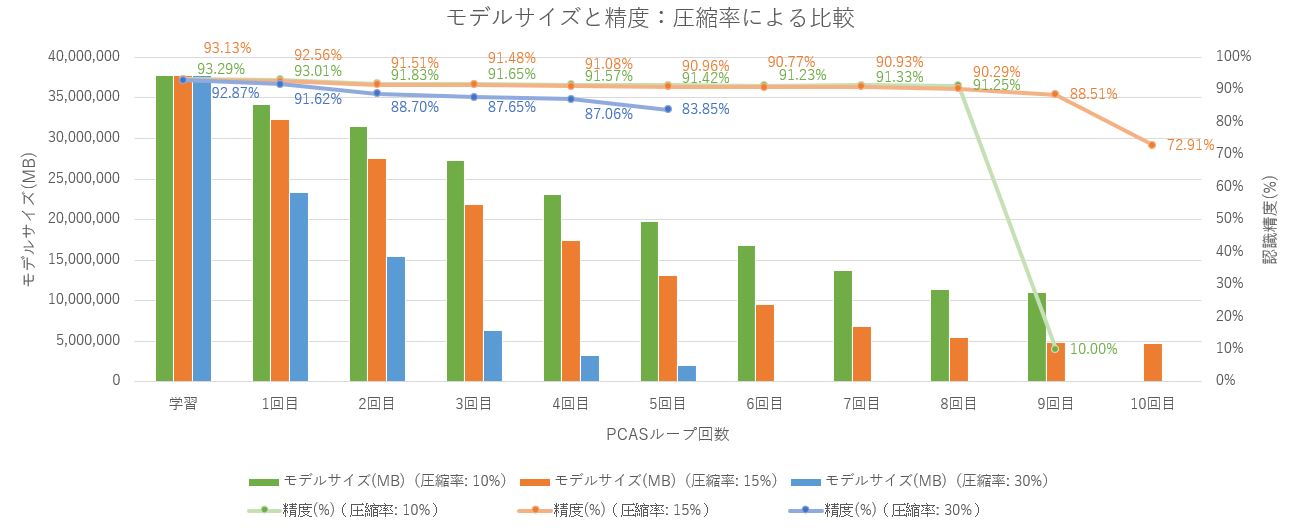
モデルサイズの変化に着目すると、どの圧縮率においても序盤のプルーニングでは大きく変化していることがわかります。圧縮率が高いとその分、モデルサイズも大きく削減されていることがわかります。
圧縮率10%のように低い場合では、プルーニング9回目で認識精度がこんなに下がったけど、実際に認識精度の低下は少ないよね。
今回は一気通貫でPCASによる軽量化を行いましたけど、それぞれ3~5時間程度と結構長い時間がかかりました。
たとえばイテレーションの数を少なめに設定して、圧縮率は高めに設定して最初は実行して、その後はイテレーションの数を多く、圧縮率を低めに設定すると効率が良くなると思います。
面白いなぁ~…。
ああ、大型のモデルの軽量化も試してみたいな…
三日三晩くらいかかるかもしれないけど…。
(昭和とは違うのだよ!昭和とは!!)
ということで、また今度。たくさん出てきた気になった点を、もっともっと検証していこう。
お楽しみに!
- ※記載されている会社名、製品名は、各社の商標または登録商標です。
- ※ここに記載されている仕様、デザインなどは予告なしに変更する場合があります。


